 Photo by Christopher Belanger (CC BY-SA 4.0)
Photo by Christopher Belanger (CC BY-SA 4.0)
A Fast, Effective, and Simple Classification Model for Customer Reviews
Summary
This post presents a new, simple, fast, and effective model for predicting a Yelp review’s star rating from its review text, including an interactive demonstration app and a downloadable R package. After motivating the project I present the theoretical model, describe how I implemented and trained it in the R programming language, and present empirical results. It is approximately 84.4% accurate when tested on a balanced set of roughly 249,000 Yelp reviews (50% positive, 50% negative), and its ROC curve shows good performance. The model is based on a simple logistic regression and runs extremely quickly when vectorised in R: it takes seconds to train on hundreds of thousands of inputs, takes seconds to test on hundreds of thousands of inputs, and takes seconds to download and install.
This work was done as part of an MBA-level directed reading course on Natural Language Processing under the supervision of Dr. Peter Rabinovitch at the University of Ottawa’s Telfer School of Management. Thank you Peter!
We also experimented with other advanced methods like lasso regression and support vector machines following Silge and Hvitfeldt (2020) and Silge and Robinson (2020), but the logistic regression model worked better and was about 1200 times faster. My entire lab notebook is available here.
Interactive Shiny App
Let’s start with the fun stuff: a Shiny app that takes user-provided input text and applies the model to predict a rating. Although this is just a toy example, it shows how you could deploy this kind of model interactively for real-time use.
If the app doesn’t load in the window above, see it in action at this link.
Motivation
An NLP classification model takes a string of text and assigns it to one of two or more classes. The problem is general and classification models have many applications in industry and academia. For example, you could use a classification model to decide whether a document is an invoice, an essay was plagiarised, or a tweet was generated by a bot.
Businesses also have a specific interest in knowing what customers are saying about their products, and more so what customers are feeling about their products. Many companies offer real-time sentiment monitoring for social media and product reviews, and these services can sift through thousands or hundreds of thousands of texts and quickly distill what the “animal spirits” are saying about a company’s products.
As a step in this direction, this project’s goal is to build a model that can accurately predict whether a Yelp review’s star rating is positive or negative from the text of the review. I used a dataset of roughly 5 million reviews that Yelp makes freely available, since using this large set of real-world data would let me build a model with a legitimate business use-case.1
The Model
This model classifies Yelp reviews as either positive or negative based on their review text. Yelp reviews actually come as integers from 1 to 5, so following common practice I classified reviews with 1 or 2 stars as negative (“NEG”), reviews with 4 or 5 stars as positive (“POS”), and discarded reviews with 3 stars (Liu 2015).
Intuitively, the model simply says that a review is more likely to be favourable if it uses more words with positive sentiment and doesn’t use the words “but” or “not” too much. The model has three pre-processing steps and a logistic function, and chooses a set of coefficients based on the input text’s length.
The first pre-processing step is to calculate the input text’s sentiment. Sentiment analysis is a rich field, but this model uses a simple dictionary-based approach based on assigning scores to positive and negative words. I’ve used a sentiment dictionary called AFINN, which is a list of 2477 words and associated sentiment scores. The word “bad,” for example, has an AFINN score of -3, the word “good” has a score of +3, and a neutral word like “because” has a score of 0. The model uses the mean AFINN score of all words in a review. In my experiments the mean worked better than the sum.
We next count the number of times “but” and “not” appear in the text. AFINN is a “bag-of-words” approach that looks words out of context without considering syntax, so it can’t tell if a word has been negated. For example, the two brief reviews “Good!” and “Not good!” will both get a score of +3, even though the second one is negative. Counting up the number of “but”s and “not”s in the text gives us a rough way of putting this information back into the model. Basically, if a text has lots of high-sentiment words but also lots of instances of the word “not,” it’s probably not a positive review.
For a given text, the recipe is as follows:
- Pre-processing:
- Calculate the mean AFINN score for the text, i.e. the sum of each word’s AFINN score divided by the number of words, and call this value
afinn_mean. - Count how many times the words “but” and “not” appear in the text: call this total
buts_nots. - Count how many words are in the text, and then find which quintile of a specified distribution it falls in. Call this value
quintile.
- Calculate the mean AFINN score for the text, i.e. the sum of each word’s AFINN score divided by the number of words, and call this value
- Predicting:
- Choose the model coefficients given by
quintile. - Find the value of the logistic function with the given coefficients and values of
afinn_meanandbuts_nots. - Interpret this function value as the probability that the text is positive.
- If the probability of being positive is > 0.5, predict the text is positive; otherwise predict it is negative.
- Choose the model coefficients given by
If we let \(\beta_n^q\) denote the \(n\)th coefficient for the \(q\)th-quintile model, the equation can be written as:
\[p(\text{text}) = \frac{1}{e^{-(\beta_0^q + \beta_1^q\times\text{afinn_mean} + \beta_2^q\times\text{buts_nots})}}\]
With the coefficients given in the following table:
| Quintile | \(\beta_0\) (Intercept) | \(\beta_1\) (AFINN_mean) | \(\beta_2\) (buts_nots) |
|---|---|---|---|
| 1 | -0.599 | 1.20 | -1.030 |
| 2 | -0.911 | 1.36 | -0.671 |
| 3 | -1.210 | 1.58 | -0.477 |
| 4 | -1.530 | 1.85 | -0.337 |
| 5 | -2.240 | 2.37 | -0.145 |
The quintiles were derived empirically from the training set of approximately 211,000 Yelp reviews, and are given in the following table:
| Quintile 1 | Quintile 2 | Quintile 3 | Quintile 4 | Quintile 5 |
|---|---|---|---|---|
| 1 - 39 | 39 - 65 | 65 - 102 | 102 - 169 | 169 - 1033 |
Demonstration
The model is implemented in an R package that’s easy to install and try out. You can get the development package from GitHub with:
# install.packages("devtools")
devtools::install_github("chris31415926535/yelpredict")Here’s a simple example that runs some test reviews through the model. I’ve written three straightforward reviews, and then one tricky one with lots of negations to try to fool the model.
library(tibble)
library(yelpredict)
review_examples <- tribble(
~"review_text", ~"true_rating",
"This place was awful!", "NEG",
"The service here was great I loved it it was amazing.", "POS",
"Meh, it was pretty good I guess but not the best.", "POS",
"Not bad, not bad at all, really the opposite of terrible. I liked it.", "POS"
)
review_examples %>%
prepare_yelp(review_text) %>%
get_prob() %>%
predict_rating() %>%
knitr::kable(col.names= c("Review Text", "True Rating", "AFINN Mean", "# Buts/Nots", "Qtile", "Log Odds", "Prob. POS", "Prediction"),
caption = "Sample review texts with true ratings, plus additional columns created by the model: The text's mean AFINN sentiment score, the number of buts/nots in the text, the text's word-length quantile, the log-odds and probability that the text is positive, and a final prediction. ")| Review Text | True Rating | AFINN Mean | # Buts/Nots | Qtile | Log Odds | Prob. POS | Prediction |
|---|---|---|---|---|---|---|---|
| This place was awful! | NEG | -3.000000 | 0 | 1 | -4.199 | 0.0147886 | NEG |
| The service here was great I loved it it was amazing. | POS | 3.333333 | 0 | 1 | 3.401 | 0.9677358 | POS |
| Meh, it was pretty good I guess but not the best. | POS | 2.333333 | 2 | 1 | 0.141 | 0.5351917 | POS |
| Not bad, not bad at all, really the opposite of terrible. I liked it. | POS | -1.750000 | 1 | 1 | -3.729 | 0.0234536 | NEG |
The first function, prepare_yelp(), takes the name of the text column and gives back a new tibble with additional columns for each review’s mean AFINN score, the number of buts/nots, and its word-length quintile. The function get_prob() takes this augmented tibble and calculates the log-odds and probability that each review is positive. Then predict_rating() turns these probabilities into predictions of either “POS” or “NEG”.
Finally, the function get_accuracy() takes the column of true ratings as an input, and will boil our final results down into one number representing the model’s predictive accuracy on the input data:
review_examples %>%
prepare_yelp(review_text) %>%
get_prob() %>%
predict_rating() %>%
get_accuracy(true_rating) %>%
knitr::kable(col.names = "Accuracy on Sample Reviews")| Accuracy on Sample Reviews |
|---|
| 0.75 |
Here we can see that the model was 75% accurate, because it got the wrong answer for the negative review that used a lot of positive words with negators (e.g. “Not bad at all”) that AFINN really can’t handle.
Note that some of these functions have optional parameters described in the package documentation.
Empirical Results
Model Accuracy
This section will show some empirical results when the model is applied to a test set of 249,053 Yelp reviews. This dataset is too large to include here(~63MB), but you can get the full set (here).
I used the first 500,000 reviews to train the model, so for testing I loaded the first million reviews and discarded the first 500,000. I next classified reviews based on their star ratings, where “POS” meant 4 or 5 stars, “NEG” meant 1 or 2 stars, and I discarded 3-star reviews following standard practice for this kind of classification task (Liu 2015). I then randomly downsampled this dataset by throwing away positive reviews until there were the same number of positive and negative reviews. Yelp reviews tend to have a left-skew distribution, where most reviews are very positive and only a few are negative, so without downsampling it would be possible to get very high accuracy by just guessing that each review is positive. On the downsampled set we would only expect to be right 50% of the time by chance.
yelp_test$rating_factor %>% summary() %>%
knitr::kable(col.names = "n",
caption = "Distribution of negative and positive reviews in test data (n=249,053).")| n | |
|---|---|
| NEG | 124526 |
| POS | 124527 |
Using the package functions, we can easily run the model on the full test set of n=249,053 reviews and measure its accuracy:
test_accuracy <- yelp_test %>%
prepare_yelp(text, qtiles) %>%
get_prob() %>%
predict_rating() %>%
get_accuracy(rating_factor)
test_accuracy %>%
knitr::kable()| accuracy |
|---|
| 0.8442821 |
The model is 0.8442821 accurate on a balanced set of 249,053 reviews from the second 500,000 reviews in the Yelp dataset. On my not-new laptop it took roughly 20 seconds to generate and score these predictions.
Sensitivity to Threshold Values
The model lets you choose the probability at which it predicts a review is positive. I’ve set a default of 0.5, but we can investigate different thresholds. Here I’ve selected 10,000 test reviews at random and set up a function to test them at 11 different thresholds ranging from 0 to 1 and then plot the results.
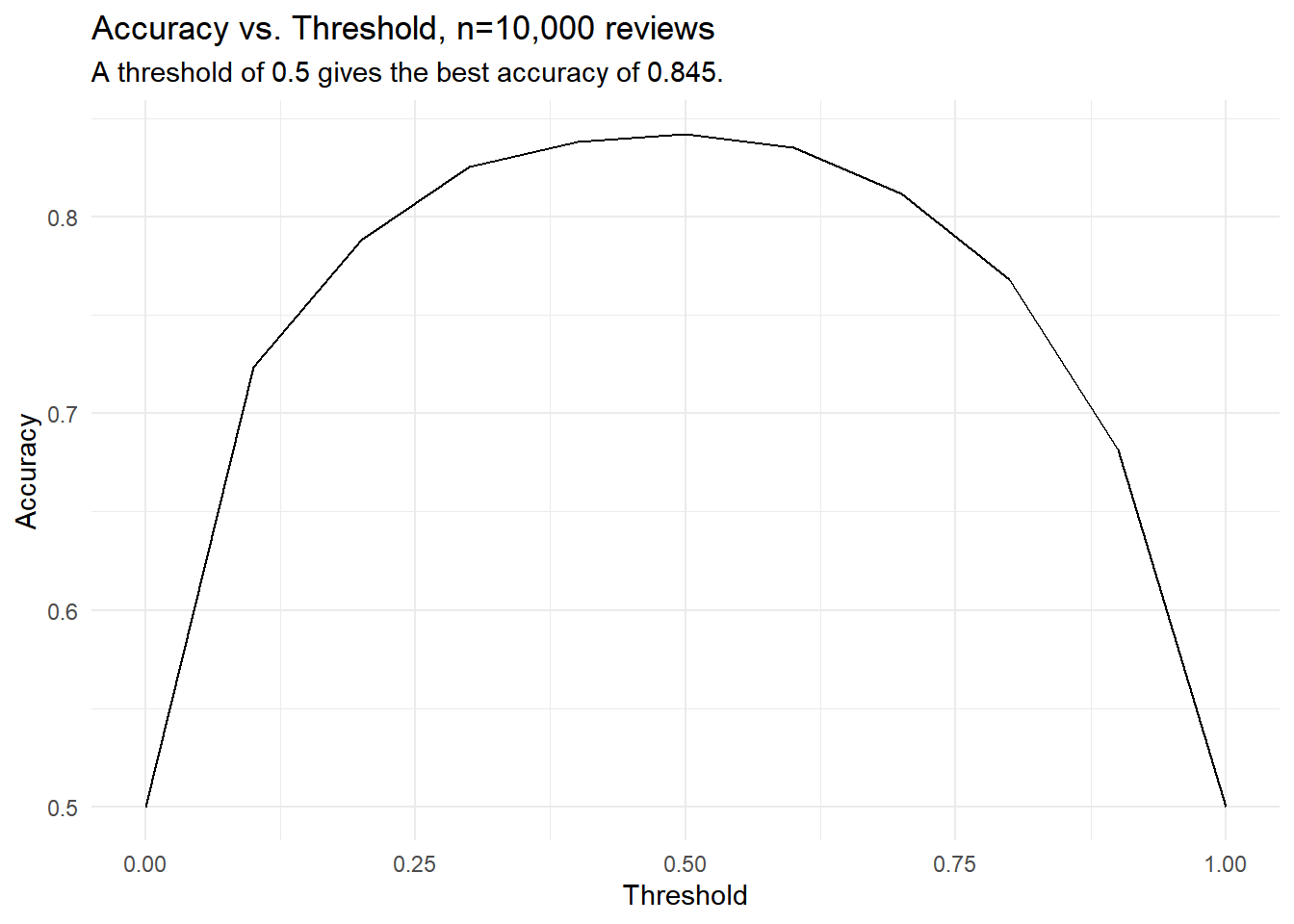
It looks like 0.5 is closest to the peak of the curve, so we have some empirical validation for the default value. Note also that the lowest success rates are 0.5 in the two cases where we say everything is negative or everything is positive. Since our dataset is balanced, we’re guaranteed to be right 50% of the time if we always give the same answer.
You might still want to use a different threshold if different errors have different costs. For example, imagine you were using these predictions to target customers for a marketing campaign. Say on average it costs \(\$ 5\) to market to a customer, and customers who left positive reviews can be expected to bring in \(\$ 6\) for an average net profit of \(\$\) 1. However, customers who left negative reviews can be expected to bring in \(\$ 0\), and so marketing to them results in a loss of \(\$ 5\). In this case, a false negative costs only \(\$ 1\), the value of the profit you missed out on by not marketing to someone who would have made a purchase. A false positive, however, costs you \(\$ 5\)! Furthermore, it takes five true-positive predictions to make up for a single false-positive error. Since our accuracy is about 84%, we can expect to get about one prediction wrong for every five we got right. All of a sudden we’re right on the borderline between profit and loss, and the folks in finance are getting heartburn! This shows a case where we might be willing to trade more false negatives to have fewer false positives.
ROC Curve
We can also plot an ROC curve to see how well the model performs in terms of false positives and false negatives.
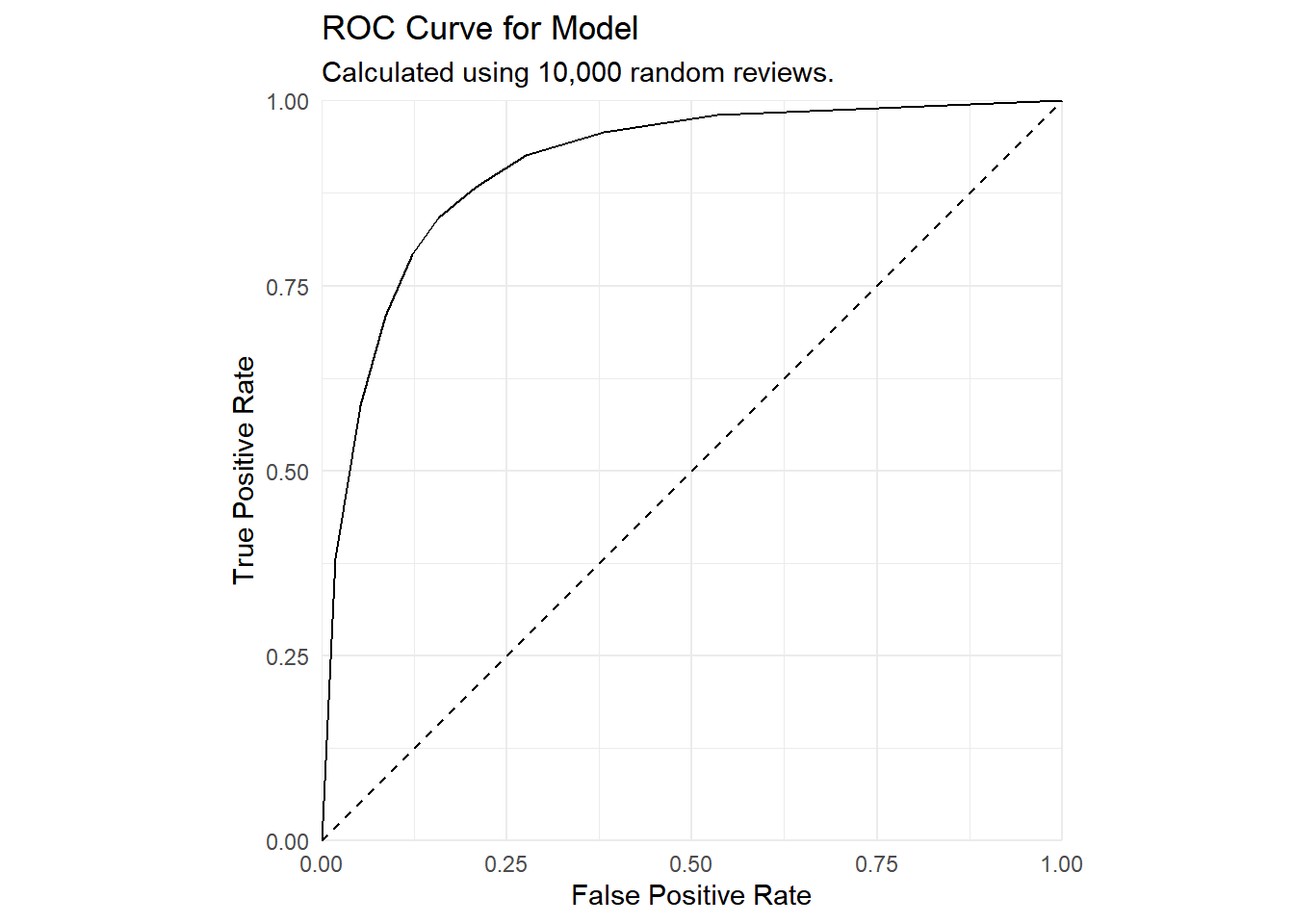
This ROC curve shows strong performance: the dashed line is what you would expect just from random guessing, and the farther the curve bows out above the better.
Reflections on Approaches to Machine Learning
This model shows that you can get great results from combining a simple and supervised approach with domain-specific knowledge. Logistic regression probably isn’t even in most people’s top 5 approaches to machine learning, but in my experiments it ran circles around more complicated and general methods like lasso regression and support vector machine classification.
The key to all this is that we knew something about reviews–good ones tend to use positive words–and used that as a starting point for experimentation. Through trial and error we learned that longer and shorter reviews are different, so we augmented the model to treat reviews differently based on how long they are. Then through some qualitative analysis we noticed that reviews with lots of negations were being misclassified, so we worked negations into the model. At each step I was able to find some new information and work it into the model to increase its accuracy.
This piecewise tinkering and improvement was only possible because logistic regression is fast. It takes a few seconds to train it on hundreds of thousands of inputs, and then a few seconds more to cross-validate it and see how it does. In contrast, testing a support vector machine on text tokens would often take over half an hour. This is a very long time to wait, especially when you’re just learning: there’s nothing like letting a training cycle run overnight only to find that it crashed halfway through because you set it up wrong. It’s not an exaggeration to say that using logistic regression let me speed up my design iterations by a factor of 1000.
To be clear, I’m not claiming that logistic regression will work in all use cases, or that other methods have no value. On the contrary, other methods like lasso regression, support vector machines, or deep-learning methods have their advantages, especially in cases where we may not have domain-specific knowledge we can bring to bear on the problem. I’m as interested and excited about these methods as anyone else, and there’ll be a blog post about them soon enough!
But this project makes it clear that if you’re looking for results, sometimes simpler is better.
Next Steps
It could be promising to extend this model using a more sophisticated sentiment-analysis algorithm. AFINN is extremely simple and doesn’t include any syntax; as I mentioned above, it can’t tell the difference between “good” and “not good.” A more complex way of measuring sentiment might therefore give even better results. However, at present I’m not aware of any better sentiment-detection algorithms that run in R at reasonable speeds.
It could also be interesting to train this model on different datasets, to see whether this approach is capturing something general about online behaviour or something specific about Yelp reviews.
Conclusions
In this blog post I’ve presented a fast and effective model for predicting Yelp ratings from text reviews. The model is 84.4% effective on a large test set, and its ROC curve shows good classification abilities. I also presented an implementation of this model in the R programming language, including an interactive Shiny app and a user-friendly package that can be downloaded and installed from GitHub. In addition, the source code is all up on GitHub and can be inspected or modified.
Resources
- Package code on GitHub: https://github.com/chris31415926535/yelpredict
- Full (unpolished) lab notebook for MBA6292: https://chris31415926535.github.io/mba6292/
- Yelp review dataset: https://www.kaggle.com/yelp-dataset/yelp-dataset
- Supervised Machine Learning for Text Analysis in R: https://smltar.com/
References
Liu, Bing. 2015. Sentiment Analysis: Mining Opinions, Sentiments, and Emotions. Cambridge: Cambridge University Press. https://doi.org/10.1017/CBO9781139084789.
Silge, Julia, and Emil Hvitfeldt. 2020. Supervised Machine Learning for Text Analysis in R. https://smltar.com/.
Silge, Julia, and David Robinson. 2020. Text Mining with R: A Tidy Approach. O’Reilly. https://www.tidytextmining.com/index.html.
In the early stages of the project I also scraped data from three web sites using three different techniques: see my lab notes here.↩︎
Christopher Belanger, PhD MBA
Data Scientist
Researcher
Policy Expert
My research interests include data science, marketing, and public policy, bridging the quantitative-qualitative divide.