
Exploring Twitter Trends with Storywrangler in R
This post will show how to do Twitter trends analysis with the Storywrangler dataset using my new R package, storywranglr. We’ll look at three worked “mini-cases”: a marketing case about Black Friday, a consumer interest case about TV shows, and a case where we link to another dataset about musicians.
About Storywrangler
Storywrangler is an enormous dataset about how people use 1-, 2-, and 3-word phrases (or “n-grams”) on Twitter from 2010 until the present and a set of tools for accessing that data. It’s updated on an ongoing basis, and it’s free to use and open-source.
For more details about Storywrangler, please see:
- Storywrangler’s web interface, which makes it easy to explore the data and look for trends.
- An academic paper in Science Advances by Storywrangler’s creators, Alshaabi et al. (2021), that gives a detailed description of the dataset and many examples. My work here is heavily indebted to theirs.
- Storywrangler’s API and documentation, which is hosted on GitHub.
About storywranglr
storywranglr is an R package that makes it easy to query Storywrangler’s data, so you can spend more time on analysis and less time parsing API call responses. It plays nicely with the tidyverse, and we’ll see some examples below of how to use it in a tidy workflow.
You can install the released version of storywranglr from CRAN with a single line:
install.packages("storywranglr")
You can also install the developer version from GitHub, which has the latest bugfixes and features, with:
devtools::install_github("chris31415926535/storywranglr")
And as always, please check out the code on GitHub.
Mini-Case 1: Black Friday and Macro-Market Trends
Is Black Friday a thing of the past with the rise of online shopping? Even before taking COVID into account, in 2019 the New York Times argued there’s "no such thing as Black Friday anymore," and in 2020 CNBC argued it’s “losing its clout”. If this were true, we might expect to see declining online interest in Black Friday in recent years.
Let’s use the function storywranglr::ngrams() to get the popularity of the 2-gram “black friday” over time. Not surprisingly, when we plot our point data it looks like there’s a regular seasonal pattern with an annual peak on Black Friday itself.
library(storywranglr)
library(tidyverse)
black_friday <- storywranglr::ngrams("black friday")
black_friday %>%
ggplot(aes(x=date, y=rank)) +
geom_point() +
theme_minimal() +
scale_y_continuous(trans = "reverse") +
labs(title = "Twitter Rank Popularity of 2-gram 'Black Friday', 2010-2021 ",
caption = "Data Source: Storywrangler ngrams API, R package storywranglr",
x = "Date",
y = "Rank") +
scale_x_date(minor_breaks = "year")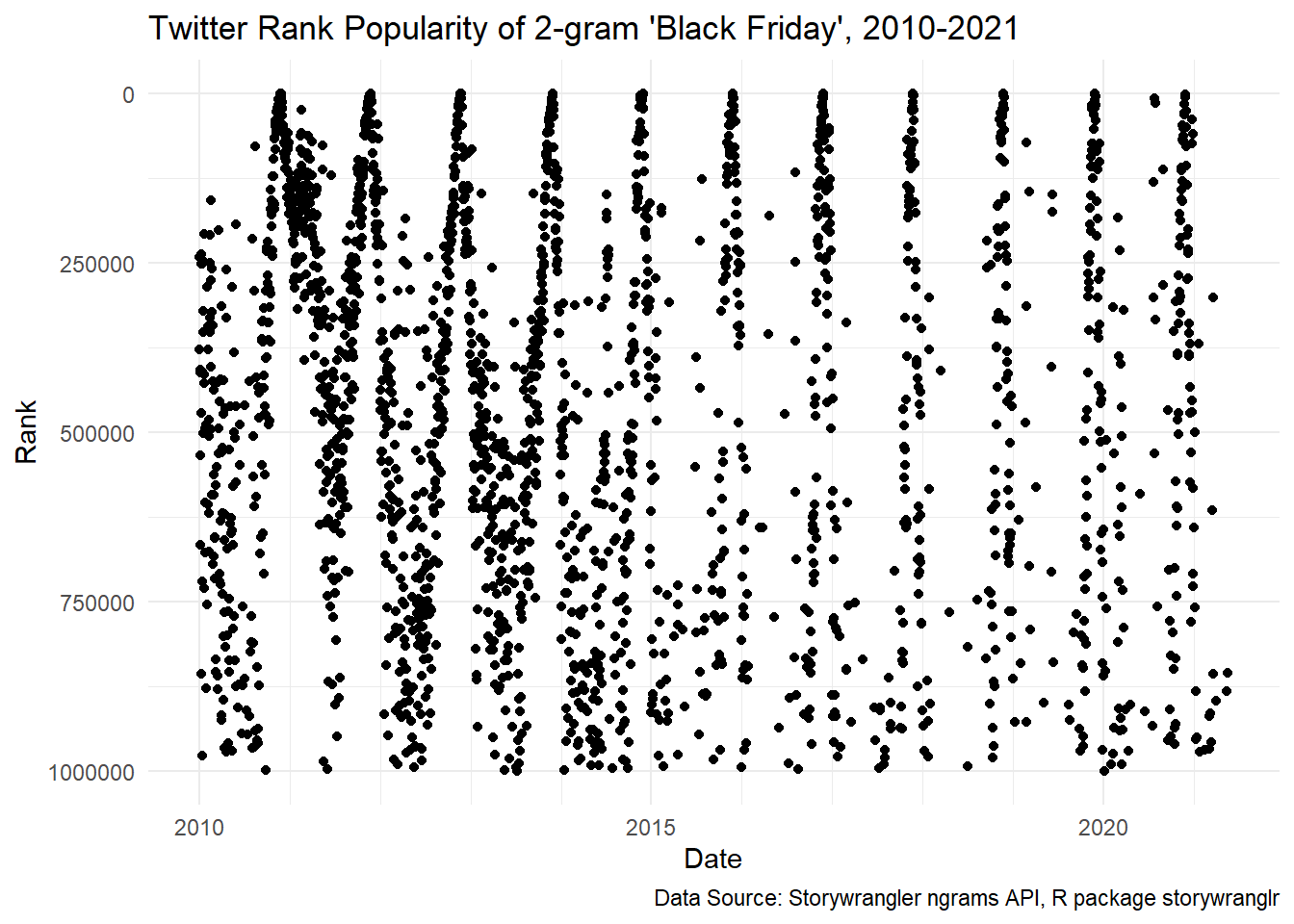
To look for long-term trends, let’s extract just the top rank for each year and plot them over time. Remember that the y-axis is inverted because a lower rank is better.
The annual peak dates are on Black Friday each year, but there’s a clear downward trend: from a peak rank of 166 in 2011, Black Friday fell to a peak rank of 894 in 2019. It fell even further in 2020 to 1,378, although we could guess that COVID helped to push it down.
# get annual peaks by finding each value's year, grouping by year, then getting
# the row with the minimum rank within each group.
black_friday_annual_peaks <- black_friday %>%
mutate(year = lubridate::year(date)) %>%
group_by(year) %>%
filter(rank == min(rank),
year < 2021)
# plot it with a linear trend line
bf_peak_plot <- black_friday_annual_peaks %>%
ggplot(aes(x=date, y = rank)) +
geom_point() +
scale_y_continuous(trans = "reverse") +
theme_minimal() +
geom_smooth(method = "lm", formula = "y ~ x") +
labs(x = "Date",
y = "Rank",
title = "Annual Top Twitter Rank Popularity of 2-gram 'Black Friday'",
subtitle = "Data Source: Storywrangler ngrams API, R package storywranglr"
)
# hat-tip to s/o https://stackoverflow.com/questions/55923256/how-do-i-keep-my-subtitles-when-i-use-ggplotly
plotly::ggplotly(bf_peak_plot) %>%
plotly::layout(title = list(text = paste0("Annual Top Twitter Rank Popularity of 2-gram 'Black Friday'",
'<br>',
'<sup>',
"Data Source: Storywrangler ngrams API, R package storywranglr",'</sup>')))This gives us some indication that online interest in Black Friday has decreased steadily over the past 10 years. A fuller study would look at more data sources, but nothing here disconfirms our suspicion that Black Friday isn’t capturing consumers’ interest the way it once did.
Mini-Case 2: TV Show Popularity
We can use Twitter data to track the relative online popularity of TV shows over time. Here we’ll look at three shows, The Walking Dead, Black Mirror, and Game of Thrones, and see how their rankings have changed over time in the Storywrangler dataset. This example recreates Figure 5d from Alshaabi et al. (2021).
Getting the data into a tidy nested tibble is a simple matter of calling storywranglr::ngrams():
# set up the shows we're looking for
tv_shows <- tibble::tibble(name = c("game of thrones",
"black mirror",
"the walking dead"))
# get the twitter data in a nested tibble using storywranglr::ngrams()
tv_shows <- tv_shows %>%
mutate(ngrams = purrr::map(name, storywranglr::ngrams, fill_dates = TRUE))Once we have our data, we can plot it on a log-scale axis to investigate the trends.
# make the basic plot
tv_plot <- tv_shows %>%
unnest(cols = "ngrams") %>%
mutate(rank = if_else(is.na(rank), 10^6, rank),
rank_mth_roll_avg = slider::slide_dbl(rank, mean, .before = 15, .after = 15),
rank_mth_roll_avg_log = log10(rank_mth_roll_avg)) %>%
ggplot(aes(x = date, y = rank_mth_roll_avg, colour = query)) +
geom_line(size = 1) +
scale_y_continuous(breaks = c(1, 5, 10, 50, 100, 500, 1000, 5000, 10000, 50000, 100000, 500000, 100000),
labels = function(x) scales::comma(x, accuracy = 1))+
scale_x_date(minor_breaks = "year") +
theme_minimal() +
theme(legend.position = "bottom") +
labs(title = "Twitter ngram ranks for popular TV shows",
subtitle = "Centred moving averages, 15 days before & after",
x = "Date",
y = "Rank",
colour = NULL)
# make it interactive
plotly::ggplotly(tv_plot) %>%
plotly::layout(yaxis = list(type = "log",
range = c(6,log10(3500)))) %>%
plotly::layout(legend = list(orientation= "h", x =0.22, y=-0.15)) %>%
plotly::layout(title = list(text = paste0("Twitter ngram ranks for popular TV shows<br>",
'<span style="font-size: 12px; ">Centred moving averages, 15 days before & after; ',
'Data from Storywrangler ngrams API, R package storywranglr</span>')
))We can get a few insights from this graph. First, it looks like The Walking Dead and Game of Thrones were neck-and-neck from about 2011 until 2017, since when GoT has had a few major peaks while TWD has declined steeply. We can also see some evidence of seasonality in GoT and TWD’s signals, and it looks like they’re phase-shifted. We might wonder if this is intentional, with the networks staggering their seasons so that they’re not competing for viewers. And finally, Black Mirror seems to be mostly absent until 2017, after which it’s in nearly the same class as GoT and TWD.
In a fuller analysis we could also pull in viewership data, episode and season finale dates, and even qualitative content analysis of online discourses to look for more trends and associations.
Mini-Case 3: Musician Age & Popularity
How old are American-born musicians when they reach peak Twitter fame? We can answer this question by joining data from Storywrangler with Panetheon’s 2020 Person Dataset, , an enormous collection of information about public figures. This analysis is also inspired by Figure 5 from Alshaabi et al. (2021).
Getting the data is simple: we load the Pantheon dataset from its csv file, filter it to only include people with occupation MUSICIAN and birthplace United States, and then call storywranglr::ngrams() to search for their names. Since we’ll be making API calls for over 1000 musicians, we’re waiting one second between requests.
# load all the people
people <- read_csv("person_2020_update.csv")
# filter only musicians from the USA and remove punctuation from names
usa_musicians <- people %>%
filter(bplace_country == "United States",
occupation == "MUSICIAN") %>%
select(name, gender, twitter, alive, birthdate, deathdate, age) %>%
mutate(name = stringr::str_replace_all(name, "[:punct:]", " "))
# get the data from Storywrangler, waiting one second between API calls
usa_musicians <- usa_musicians %>%
mutate(result = purrr::map(name, function(x) {
message(x)
Sys.sleep(1)
storywranglr::ngrams(x)
}))Now we have our data in a nice nested tibble: one row per musician, with one column that contains each musician’s entire Twitter ngram history.
To get some useful information, for each musician we can find the day where they had their best (i.e. lowest) Twitter ngram rank, and how old they were when it happened.1 This only takes a few lines. Let’s look at the 10 top-rated musicians:
# get the statistics for the date when each musician had their lowest (i.e. best) rank
# then find their age at their best rank, then get the log10 of the best rank
usa_musicians_best <- usa_musicians %>%
filter(name != "Sonny Boy Williamson I") %>%
mutate( temp_column = purrr::map(result, function(x) filter(x, rank == min(rank)))) %>%
unnest(cols = "temp_column") %>%
mutate(birthdate = as.Date(birthdate)) %>%
mutate(age_at_min_rank = lubridate::time_length(date - birthdate, unit = "years"),
log_min_rank = log10(rank)) %>%
select(-result) %>%
distinct(name, rank, .keep_all = TRUE)We can use a density plot to get a feel for the overall distribution, to see if there are age clusters where musicians tend to have the most Twitter popularity.
# make a filled 2d density plot of age at best rank and the log10 value of the best rank
usa_musicians_best %>%
ggplot(aes(x=age_at_min_rank,
y=log_min_rank)) +
geom_density2d_filled() +
scale_y_continuous(trans = "reverse") +
theme_minimal() +
theme(legend.position = "none") +
labs(x = "Age at Top Rank",
y = "Log10 of Top Rank",
title = "Density Plot of American-Born Musicians' Ages at Top Twitter Rank",
caption = "Data Sources: Storywrangler ngrams API, Pantheon 2020 People Dataset,\nR package storywranglr")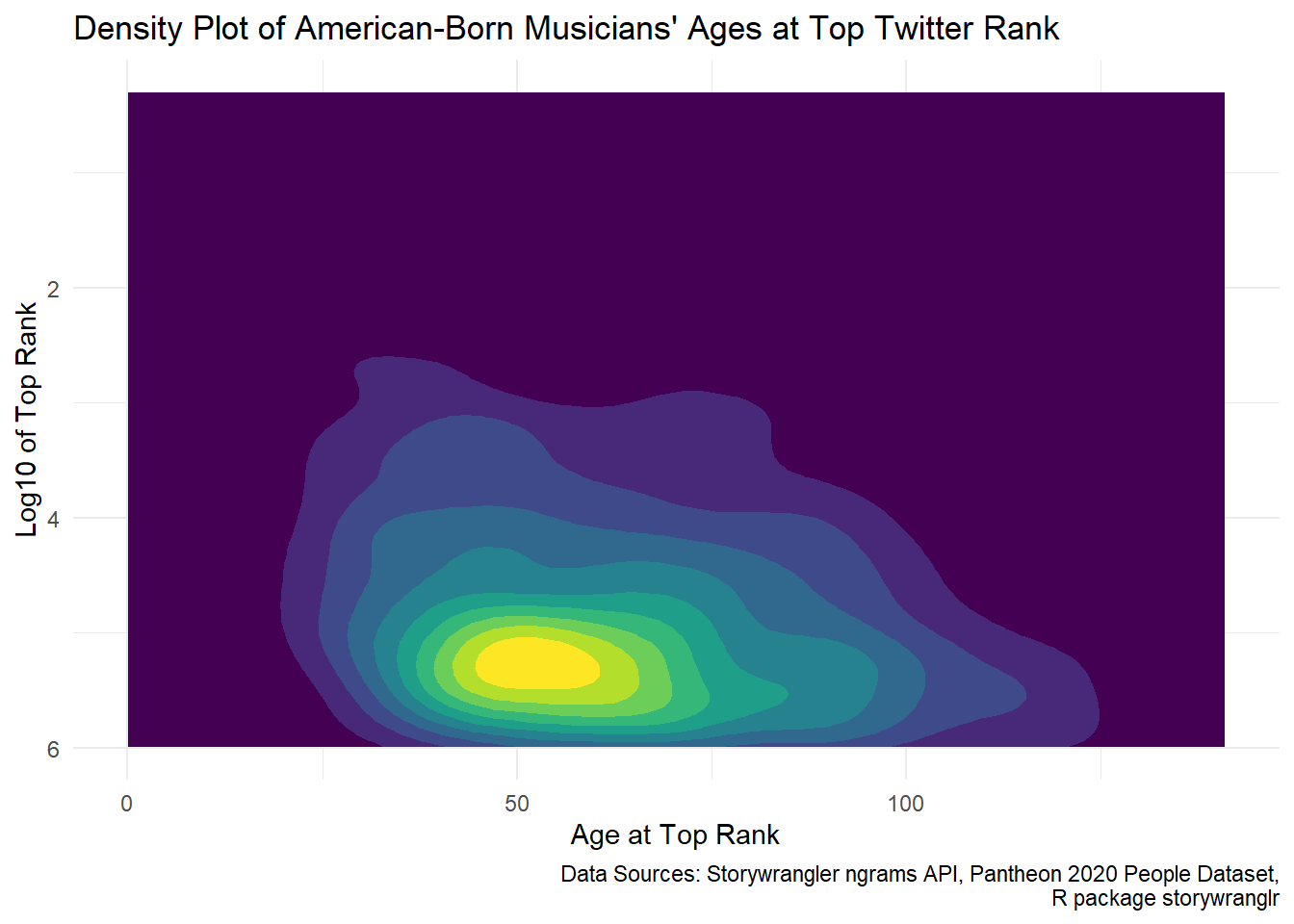
It looks like overall musicians achieve peak Twitter popularity around age 50–not what I would have guessed! That there’s a long tail to the right, including some peaks at over 100 years of age. We might wonder if this is related to fans expressing joy as elder musicians celebrate birthdays, and grief as they pass away. The peak rank is also pretty low at around 500,000, although it looks like some break into the top 10 Twitter ngrams.
To check out some specifics, let’s look at the 10 top-rated musicians from the dataset:
# select the valeus we want, round the numeric values, then put the top 10 in a table
usa_musicians_best %>%
select(name, birthdate, rank , date, age_at_min_rank) %>%
mutate(age_at_min_rank = round(age_at_min_rank, digits = 0),
rank = round(rank, digits = 0)) %>%
arrange(rank) %>%
head(10) %>%
reactable::reactable(columns = list(
name = colDef(name = "Name"),
birthdate = colDef(name = "Birthdate", align = "center"),
rank= colDef(name = "Rank", align = "center"),
date = colDef(name = "Date of Top Rank", align = "center"),
age_at_min_rank = colDef(name = "Age at Top Rank", align = "center")
),
outlined = TRUE)This looks good, except we have one false positive: while John Lewis was an incredible musician, his peak here came one day after the American politician John Lewis passed away. So for precise analyses, we’ll need to make sure we’re looking at the right person.
Still, we might wonder–is there an association between a musician’s death and the volume of discussion about them on Twitter? Let’s look at the subset of musicians who passed away since the beginning of Storywrangler’s dataset in January 2010, find the number of days that passed between their death and their peak twitter rank, remove any values greater than 1000 days, and make a histogram:
# make a ggplot histogram
peak_date_hist <- usa_musicians_best %>%
filter(deathdate > as.Date("2010-01-08")) %>%
mutate(deathdate = as.Date(deathdate),
diff = date - deathdate) %>%
filter(abs(diff) < 1000) %>%
ggplot() +
geom_histogram(aes(x=diff), fill = "#123456") +
theme_minimal() +
labs(y = "Days",
x = "Count")
# make it interactive
plotly::ggplotly(peak_date_hist) %>%
plotly::layout(title = list(text = paste0("Days Between Death and Peak Twitter Rank, American Musicians"),
y = 0.99)) %>%
plotly::add_annotations(
x=-0.4,
y=66,
xref = "x",
yref = "y",
text = "Data Sources: Storywrangler ngrams API, Pantheon 2020 People Dataset",
xanchor = 'left',
showarrow = F
)It sure looks like there’s an association between a musician’s death and their peak Twitter rank: removing outliers, the vast majority of them peak either the day of or the day after their deaths.
What’s Next?
This is just a sample of what’s possible with Storywrangler’s data, and I hope I’ve convinced you it’s easy to get and work with this data in R using storywranglr. If you have questions or ideas, please don’t hesitate to get in touch.
I removed Sonny Boy Williamson I, since Storywrangler only tracks sequences of 1, 2, or 3 words.↩︎