Web Scraping in R: Selenium, FireFox, and PhantomJS
This tutorial will show you how to scrape web pages in R using the packages RSelenium and wdman. We’ll cover both browser-enabled scraping using Firefox and “headless” scraping using PhantomJS. As a case study, we’re going to collect a set of press releases from the Government of Ontario and do a bit of pre-processing so we can do some natural language processing later.
If you want to skip to the code to make this work, it’s available here at the bottom of the post.
If you want to download the dataset it’s available on GitHub here, or you can look at it right now by installing in R as follows:
devtools::install_github("chris31415926535/ogreleases")
df <- ogreleases::ogreleases_dataMotivation: Scraping Government of Ontario News Releases
I’ve been working through the excellent (and free!!) book Supervised Machine Learning for Text Analysis in R by Emil Hvitfeldt and Julia Silge, and wanted to try out some of their techniques on a new dataset. Since I’m interested in applying machine learning techniques to public policy questions, I decided to try my hand at createing a dataset of publicly available press releases issued by the Government of Ontario.
But while Ontario’s press releases are technically available online, the Ontario Newsroom is a Javascript-enabled nightmare that shows results 10 at a time in reverse chronological order each time you click a button. This is, and I cannot stress this enough, dumb: if you want to find a press release from last year, you will have to click the ridiculous button over 300 times. It’s like putting your entire library catalogue online but only showing users the last 10 books you happened to put on the shelves.
Basic web-scraping techniques based on pure html or css won’t work here, and our only other option is to sit there clicking the ridiculous button for hours on end. Enter RSelenium!
Some New Tools: Selenium, RSelenium, and PhantomJS
For this tutorial we’ll need three new tools: Selenium, RSelenium, and PhantomJS.
Selenium’s developers claim that “Selenium automates browsers. That’s it!”, and frankly it’s tough to improve on that summary. We’ll be using it for a very simple purpose: connecting to a browser instance, navigating it to the Ontario Newsroom, and then having our computer click the ridiculous button 1,000 times to load 10,000 media releases. There’s just something aesthetically pleasing about using a complex technological workaround to solve a dumb UI problem!
RSelenium is an R package that does exactly what its name might suggest, and lets us interact with Selenium through R. You can download it through its CRAN page, or as usual through R’s package manager.
PhantomJS is a scriptable headless web browser. “Headless” here means that it doesn’t connect to any kind of graphical user interface–it just runs in the background, doing web stuff. Normally this is the exact opposite of what you want in a web browser (it’s no good knowing that your computer is looking at cat gifs if you can’t see them), but here it’s perfect since we just want to automate basic tasks and extract the results.
With this knowledge, we’re ready to get started!
Part 1: Installing and Testing Stuff
First we’ll make sure that we have and can load all the packages we need. I’m also loading the full tidyverse since we’ll use some of those functions later on for preprocessing our results.
install.packages(c("RSelenium", "wdman", "tidyverse"))
library(tidyverse)
library(RSelenium)
library(wdman)Part 2: Testing with Firefox
Next we’ll set up RSelenium to automatically manage an instance of Firefox. I found it helpful to start this way because I could actually see what was happening. We’ll move on the PhantomJS once we’ve got this step working.
First, we start a Selenium server and browser using the command rsDriver(). This function gives us a lot of options, but we’ll settle for specifying the port (4567, for aesthetic purposes) and browser (Firefox, because it was the first one I tried and it worked). Assuming it worked, rsDriver() returned a list named rD that contains a server and a client. We only care about the client, so we’ll extract it into another variable called rDC like so:
# Start Selenium using Firefox on port 4567
rD <- rsDriver(browser = "firefox", port = 4567L)
# For convenience, get a variable pointing to the client
rDC <- rD$clientYou should expect to see a bunch of information printed to the console, and then a new Firefox browser window should open up. If so, congrats! If not, consider the following:
- Make sure you have Firefox installed.
- Alternatively, you can try using another browser by setting, for example,
browser = "chrome". - Otherwise, your answer may lie somewhere in
RSelenium’s documentation. Good luck!
Once you have RSelenium working and you’ve started a browser session, basic web browsing is pretty easy. This next command tells our Firefox browser to load the Ontario Newsroom, and when you execute it you should see that page load in Firefox.
# Navigate our RSelenium browser session to the Governmente of Ontario Newsroom
rDC$navigate("https://news.ontario.ca/en/")Success! But this is the point where we run into the Newsroom’s dumb design and the ridiculous button, since we can only see the 10 most-recent news releases. How can we tell RSelenium to click the ridiculous button? First we need to figure out how to identify it in the alphabet soup of html, css, and JS that makes up modern web design.
Enter SelectorGadget, a point-and-click tool to help you extract specific bits of a webpage using css selectors. It’s very easy to use and the documentation is great, so I’ll skip to the punchline that the ridiculous button is uniquely identified by the css selector “.mb-5”.
So we can extract that button as follows, using findElement():
# find the button
button <- rDC$findElement(using = "css", value = ".mb-5")Next, we will summon the full power of Selenium to… push TRB 1,000 times.
# click the button 1000 times
for (i in 1:1000) button$clickElement()Note that this will take forever because, as I have stressed above and am morally bound to continue to stress, the Ontario Newsroom is dumb. I let this loop run for a few hours in Firefox and it went through 416 clicks and loaded items back to January 18, 2019. I tried again using PhantomJS (as described below) and was able to click 556 times in about 4 hours before it just stopped working and I had to restart R.
For Science(TM) I ran the following script to record time time taken to click TRB 200 times. Something weird starts happening around 60 clicks (for those interested, raw results are available here), but if we break the data into groups of 10 clicks and plot the average time taken for each group we see a clear upward trend:
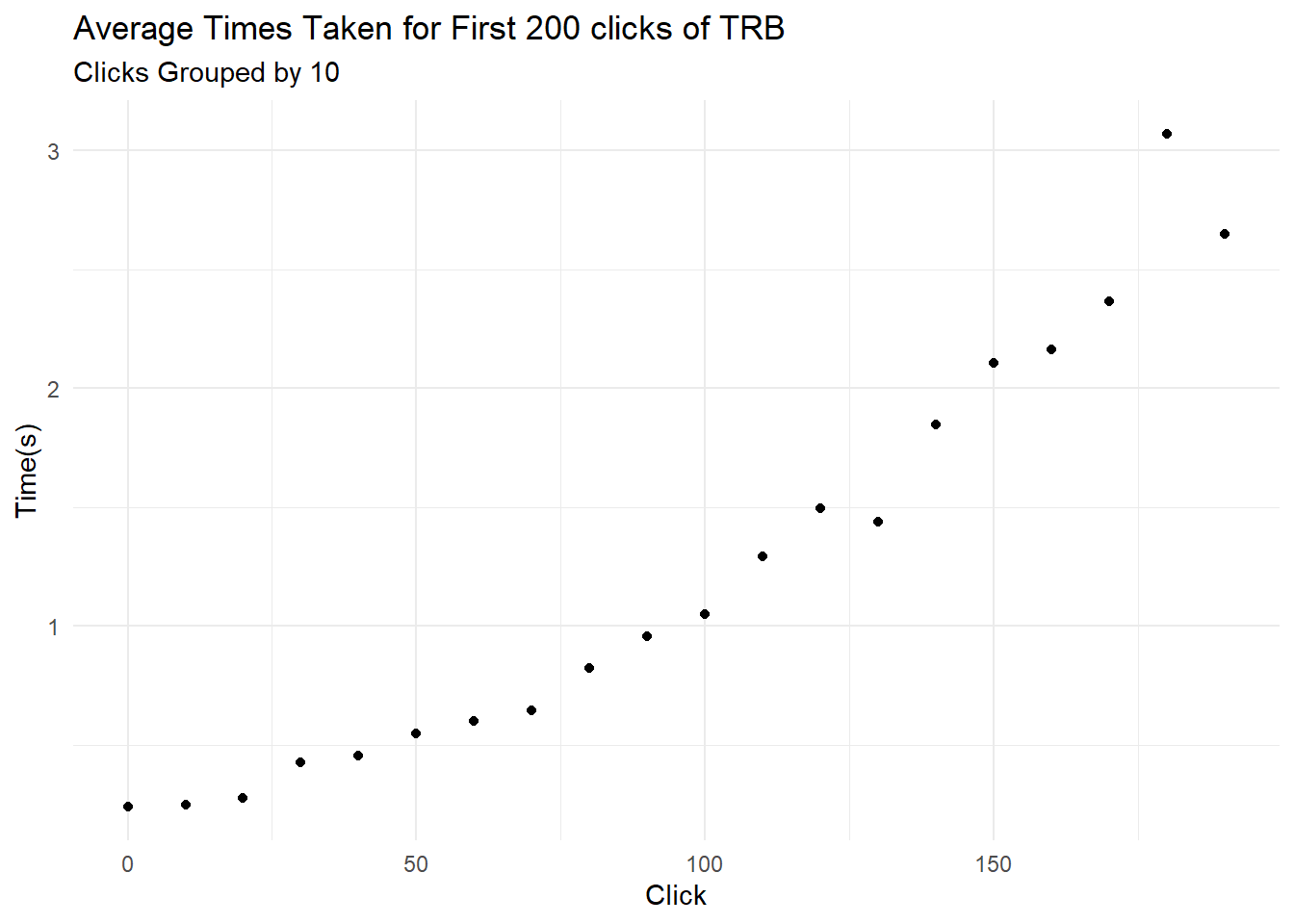
I suspect but cannot prove that this is because the Ontario Newsroom is–say it with me–dumb, and browsers just aren’t built to manage dynamic webpages with many thousands of entries. The ontario Newsroom was made to look pretty, not to provide access to information.
At any rate, now that we’ve clicked TRB we may as well look at the data we’ve collected. I wasn’t able to use css selectors for this, but the second-easiest way is just to find all the urls on the page and then focus on the ones we’re interested in. We’ll do this by searching xpath, which you can read a bit more about here. Once we have a set of RSelenium objects corresponding to the urls on the webpage, we’ll use a workmanlike for-loop to extract the urls as character vectors.
# search for all urls on the page by xpath
links <- rDC$findElements(using="xpath", value="//a[@href]")
# set up a vector to contain our raw urls
link_raw <- vector(mode="character",length=length(links))
# extract the raw urls
for (i in 1:length(link_raw)){
link_raw[[i]] <- links[[i]]$getElementAttribute("href")[[1]]
}Next we’ll put our results in a tibble. We know that the links we’re interested in all point to a page on https://news.ontario.ca/en/, contain a numeric identifier, and include the text “release”, so we’ll use a simple regular expression to filter out anything else.
# filter for the links we're interested in
link_tib <-
link_raw %>%
as_tibble() %>%
filter(str_detect(value, "news\\.ontario\\.ca/en"),
str_detect(value, "[:digit:]"),
str_detect(value, "release"))Here are the first five links from when I ran the code:
This is what we’ve been waiting for! Now we can finally start scraping some web data!
Scraping the web data is pretty easy in comparison to what we’ve done so far. For each link we tell RSelenium to load the page, we extract some relevant information using css selectors, and we put that information into a results tibble. This code chunk does all that using, again, a workmanlike for loop and some decidedly un-tidy indexing. But it works, and I’m a strong proponent of third-best solutions that work!
# would you like updates to the console?
verbose <- TRUE
# turn tibble into vector for working with it in a loop
link_vec <- link_tib %>% unlist()
# how many links we have
len = length(link_vec)
# set up our results tibble
results <- tibble(title = rep(NA_character_, len),
subtitle = rep(NA_character_, len),
date = rep(NA_character_, len),
issuer = rep(NA_character_, len),
plain_text = rep(NA_character_, len),
html_source = rep(NA_character_, len),
url = rep(NA_character_, len))
# another workmanlike loop.
# we load each page, extract the information we want, and add it to our results.
# we also do a lot of waiting around for pages to load to prevent system crashes.
for (i in 1:len){
rDC$navigate(link_vec[[i]])
if (verbose) message(paste0(i," : ",link_vec[[i]]))
# sleep 2 seconds to let the browser load
Sys.sleep(2)
# if we're not finding the elements, keep sleeping: the browser isn't loaded yet
while (length(rDC$findElements(using = "css", value = "#release_intro .release_title_mobile")) == 0) Sys.sleep(2)
if (verbose) message ("reading..")
title <- rDC$findElement(using = "css", value = "#release_intro .release_title_mobile")$getElementText()[[1]]
subtitle <- rDC$findElement(using = "css", value = ".ontario-lead-statement")$getElementText()[[1]]
date <- rDC$findElement(using = "css", value = "#release_intro strong")$getElementText()[[1]]
issuer <-rDC$findElement(using = "css", value = ".mb-0+ .mb-0")$getElementText()[[1]]
plain_text <- rDC$findElement(using = "css", value = "div+ .release_print_row .col-lg-8")$getElementText()[[1]]
html_source <- rDC$findElement(using = "css", value = "div+ .release_print_row .col-lg-8")$getElementAttribute("innerHTML")[[1]]
results[i,]$title <- title
results[i,]$subtitle <- subtitle
results[i,]$date <- date
results[i,]$issuer <- issuer
results[i,]$plain_text <- plain_text
results[i,]$html_source <- html_source
results[i,]$url <- link_vec[[i]]
}We’ll do some minimal clean-up on the plaintext to remove the table of contents at the top of each release:
# minimal data cleaning to remove table of contents from plain text
results <- results %>%
mutate(plain_text = str_remove_all(plain_text, regex("Table of Contents(.*?)Related Topics\\n", dotall = TRUE)))And that’s it! Here are the first five results from when I ran the code to prepare this blog post. We can see there’s still something strange going on with unicode, but that’s a problem for another day:
| Issuer | Date | Title | Plain Text |
|---|---|---|---|
| Office of the Premier | September 16, 2020 | Ontario Launches New COVID-19 Screening Tool to Help Protect Students an… | TORONTO — The Ontario government launched a new voluntary interactive sc… |
| Office of the Premier | September 15, 2020 | Province Ramps Up Production of Ontario-Made Ventilators | GUELPH <U+2015> The Ontario government is investing $2.5 million through the On… |
| Office of the Premier | September 14, 2020 | Health Preparedness and Rebuilding the Economy Top Priorities in Ontario… | TORONTO — The Ontario government is returning to the legislature today, … |
| Health | September 14, 2020 | Ontario Investing in Hospital Upgrades and Repairs | MISSISSAUGA — The Ontario government is investing $175 million this year… |
| Office of the Premier | September 16, 2020 | Ontario Launches New COVID-19 Screening Tool to Help Protect Students an… | TORONTO — The Ontario government launched a new voluntary interactive sc… |
Part 3: PhantomJS
It’s possible to do this entire process using PhantomJS, which is essentially a web browser without a GUI. This is terrible for watching dog videos, but it’s great for automating boring tasks when you don’t actually need to have a visible web browser open.
The process for doing this in PhantomJS is nearly the same as for Firefox except you need to use the wdman package.,I’m only presenting the code here because I couldn’t find a working example anywhere else.
# load the requisite library
library(wdman)
# start phantomjs instance
rPJS <- wdman::phantomjs(port = 4680L)
# is it alive?
rPJS$process$is_alive()
#connect selenium to it?
rJS <- RSelenium::remoteDriver(browserName="phantomjs", port=4680L)
# open a browser
rJS$open()
# away to the races!When I tried this it wasn’t noticeably faster than using Firefox and it actually crashed around 500 clicks, so there’s no clear benefit to using it here.
Summary
So what have we accomplished? It depends on how charitable you’re feeling. On the one hand, we learned how to scrape dynamic webpages using RSelenium and extracted machine-readable information about the Ontario Government’s press releases that can be used to practice natural-language processing techniques. On the other hand, we spent a few hours writing a computer program to (drumroll) press a button that shouldn’t have been there in the first place.
The point, of course, is that this will let us do some fun natural-language processing using real data with some Made-in-Ontario public policy implications! But that’ll have to wait for a future post.
Complete Code
For web scraping using Firefox:
install.packages(c("RSelenium", "wdman", "tidyverse"))
library(tidyverse)
library(RSelenium)
library(wdman)
# Start Selenium using Firefox on port 4567
rD <- rsDriver(browser = "firefox", port = 4567L)
# For convenience, get a variable pointing to the client
rDC <- rD$client
# Navigate our RSelenium browser session to the Governmente of Ontario Newsroom
rDC$navigate("https://news.ontario.ca/en/")
# find the button
button <- rDC$findElement(using = "css", value = ".mb-5")
# click the button 200 times
for (i in 1:200) button$clickElement()
# search for all urls on the page by xpath
links <- rDC$findElements(using="xpath", value="//a[@href]")
# set up a vector to contain our raw urls
link_raw <- vector(mode="character",length=length(links))
# extract the raw urls
for (i in 1:length(link_raw)){
link_raw[[i]] <- links[[i]]$getElementAttribute("href")[[1]]
}
# filter for the links we're interested in
link_tib <- link_raw %>%
as_tibble() %>%
filter(str_detect(value, "news\\.ontario\\.ca/en"),
str_detect(value, "[:digit:]"),
str_detect(value, "release"))
# would you like updates to the console?
verbose <- TRUE
# turn tibble into vector for working with it in a loop
link_vec <- link_tib %>% unlist()
# how many links we have
len = length(link_vec)
# set up our results tibble
results <- tibble(title = rep(NA_character_, len),
subtitle = rep(NA_character_, len),
date = rep(NA_character_, len),
issuer = rep(NA_character_, len),
plain_text = rep(NA_character_, len),
html_source = rep(NA_character_, len),
url = rep(NA_character_, len))
# another workmanlike loop.
# we load each page, extract the information we want, and add it to our results.
# we also do a lot of waiting around for pages to load to prevent system crashes.
for (i in 1:len){
rDC$navigate(link_vec[[i]])
if (verbose) message(paste0(i," : ",link_vec[[i]]))
# sleep 2 seconds to let the browser load
Sys.sleep(2)
# if we're not finding the elements, keep sleeping: the browser isn't loaded yet
while (length(rDC$findElements(using = "css", value = "#release_intro .release_title_mobile")) == 0) Sys.sleep(2)
if (verbose) message ("reading..")
title <- rDC$findElement(using = "css", value = "#release_intro .release_title_mobile")$getElementText()[[1]]
subtitle <- rDC$findElement(using = "css", value = ".ontario-lead-statement")$getElementText()[[1]]
date <- rDC$findElement(using = "css", value = "#release_intro strong")$getElementText()[[1]]
issuer <-rDC$findElement(using = "css", value = ".mb-0+ .mb-0")$getElementText()[[1]]
plain_text <- rDC$findElement(using = "css", value = "div+ .release_print_row .col-lg-8")$getElementText()[[1]]
html_source <- rDC$findElement(using = "css", value = "div+ .release_print_row .col-lg-8")$getElementAttribute("innerHTML")[[1]]
results[i,]$title <- title
results[i,]$subtitle <- subtitle
results[i,]$date <- date
results[i,]$issuer <- issuer
results[i,]$plain_text <- plain_text
results[i,]$html_source <- html_source
results[i,]$url <- link_vec[[i]]
}
# minimal data cleaning to remove table of contents from plain text
results <- results %>%
mutate(plain_text = str_remove_all(plain_text, regex("Table of Contents(.*?)Related Topics\\n", dotall = TRUE)))For web scraping using PhantomJS:
# load the requisite library
library(wdman)
# start phantomjs instance
rPJS <- wdman::phantomjs(port = 4680L)
# is it alive?
rPJS$process$is_alive()
#connect selenium to it?
rJS <- RSelenium::remoteDriver(browserName="phantomjs", port=4680L)
# open a browser
rJS$open()
# then follow the code in the Firefox exampleFor benchmarking how long it takes to click TRB:
# load the library tictoc, which we'll use to track how long each click takes
library(tictoc)
# set up a vector for our durations
times <- vector(mode="double", length=200L)
# Navigate our RSelenium browser session to the Governmente of Ontario Newsroom
rDC$navigate("https://news.ontario.ca/en/")
# find the button
button <- rDC$findElement(using = "css", value = ".mb-5")
# click 200 times and record how long each click takes
for (i in 1:200){
tic()
button$clickElement()
q <- toc()
times[[i]] <- q$toc - q$tic
}
# put our vector into a tibble
click_times <- tibble(times = times) %>%
rowid_to_column() %>%
rename(click=rowid, delay=times)
# make a plot
click_times %>%
ggplot() +
geom_point(aes(x=click, y=delay)) +
labs(
title="Time taken for the first 200 clicks of TRB",
x="Click",
y="Time(s)"
) +
theme_minimal()Christopher Belanger, PhD MBA
Data Scientist
Researcher
Policy Expert
My research interests include data science, marketing, and public policy, bridging the quantitative-qualitative divide.